Using PropEr with erlang.mk
Sunday, 7th July, 2019
I have started working through Fred Hebert’s excellent Property-Based Testing with PropEr, Erlang, and Elixir (old but free version here). (n.b., PropEr’s own website is here). I plan to add property-based tests to my LIGA project.
Chapter 1 shows how to call PropEr from rebar3 (amd mix for Elixir). However, I prefer erlang.mk for my own projects, so here is a brief note on calling PropEr from erlang.mk.
*** howto
First, add PropEr as a test dependency to your Makefile:
TEST_DEPS = proper
Then …
$ make proper
… will run all the prop_*.erl files in test/
*** book example
For a quick look at usage & output I copied the book’s prop_base.erl into LIGA’s test/ directory.
First, using the failing version of prop_base.erl on p. 25:
$ make proper
GEN test-dir
GEN test-build
GEN proper
Testing prop_base:prop_biggest/0
.!
Failed: After 2 test(s).
An exception was raised: error:function_clause.
Stacktrace: [{prop_base,biggest,[[]],[{file,"test/prop_base.erl"},{line,22}]},
{prop_base,'-prop_biggest/0-fun-0-',1,
[{file,"test/prop_base.erl"},{line,19}]}].
[]
Shrinking (0 time(s))
[]
erlang.mk:6880: recipe for target 'proper' failed
make: *** [proper] Error 1
Second, using the succeeding version of prop_base.erl on p. 27:
$ make proper
GEN test-dir
GEN test-build
GEN proper
Testing prop_base:prop_biggest/0
....................................................................................................
OK: Passed 100 test(s).
*** next steps
- create generators for LIGA data types
- create properties for LIGA functions
- get them working, make them beautiful, …
Dialyzing legacy code
Wednesday, 3rd July, 2019
** Introduction
Typespecs are handy documentation for erlang functions, but they really come to life when used with Dialyzer []. Dialyzer analyzes a codebase and checks that functions behave according to their typespec. This post runs quickly through using dialyzer on an existing codebase, my own LIGA project.
** Preparation
First, build a PLT (Persistent Lookup Table) for the project. Include a list of erlang apps the project uses, and provide a project-specific location:
$ dialyzer --build_plt --apps kernel stdlib erts eunit --output_plt .liga.plt Compiling some key modules to native code... done in 0m25.63s Creating PLT .liga.plt ... Unknown functions: compile:file/2 compile:forms/2 compile:noenv_forms/2 compile:output_generated/1 crypto:block_decrypt/4 crypto:start/0 Unknown types: compile:option/0 done in 0m24.01s done (passed successfully)
This will output a dialyzer PLT in a newly-created local file .liga.plt.
More applications can be added after building:
$ dialyzer --add_to_plt --apps compiler crypto --plt .liga.plt
It is possible to run Dialyzer over a whole codebase in one sweep. The simplest way is to give dialyzer a list of directories to analyse, e.g.:
$ dialyzer -r src/ test/ --src
The --src flag tells dialyzer to find and check .erl files (default is to check compiled .beam files).
Build tools like erlang.mk have wrappers too, e.g.:
$ make dialyze
When dialyzing a legacy codebase, the above is likely to produce a lot of warnings, so going module-by-module might be more manageable. Here is a simple workflow:
$ dialyzer src/liga_intmap.erl- [… edit liga_intmap.erl as desired …]
$ make$ dialyzer --add_to_plt -c ebin/liga_intmap.beam --plt .liga.plt
The last step adds the functions in the module to the PLT. Once the whole codebase has been done for the first time, future checks in batch mode (i.e., after changes to the code) should return with few or no warnings.
When dialyzing a codebase module-by-module, we check each module, make any desired changes, then recompile the code and add the module’s beam file (along with any other updated beam files) to the project’s PLT. Dialyzer will issue warnings for any “unkown functions” (i.e., functions in modules it doesn’t know about). To avoid as many of these as possible, we go through the modules working up the dependency tree, starting at leaf modules (without dependencies).
Grapherl can render a dependency tree of erlang modules as a .png file, e.g.:
$ grapherl -m ebin/ liga.png
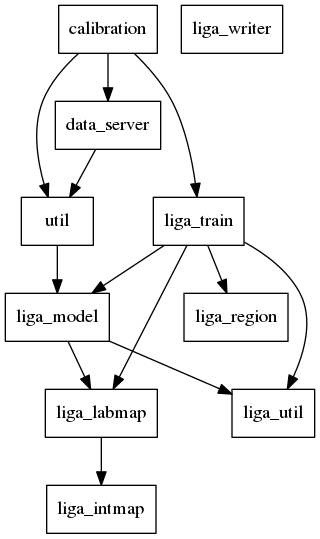
Here are some example warnings I got when dialyzing LIGA.
labmap.erl
$ dialyzer src/liga_labmap.erl Checking whether the PLT .liga.plt is up-to-date... yes Proceeding with analysis... liga_labmap.erl:77: The pattern can never match the type done in 0m0.14s done (warnings were emitted)
Dialyzer doesn’t see macros (including records). As the line defining ?VERSION as original is commented out, the clause of versioned_weights/3 that matches it appears to be superfluous.
data_server.erl
$ dialyzer src/data_server.erl
Checking whether the PLT .liga.plt is up-to-date... yes
Proceeding with analysis...
data_server.erl:82: The created fun has no local return
data_server.erl:83: The call data_server:get_with_complement(Lab::any(),Ra::any(),{'nm',_},0) breaks the contract (atom(),any(),pcage(),non_neg_integer() | 'all') -> {[labelled_string()],[labelled_string()]}
done in 0m0.22s
done (warnings were emitted)
“no local return”
– this can mean that the specified function never returns, in which case the typespec can mark the function’s return type as no_return(). It can also (perhaps more often) mean that dialyzer itself crashed while checking the function. In my experience the next warning gives a clue to the cause of the crash.
“breaks the contract”
– there is a mismatch between type expectations between calling function and function being called. The error might just be in the typespec annotations — or two parts of the codebase might have gotten out of sync. In either case tis is important to resolve.
liga_writer.erl
This warning is from erlang.mk’s ‘make dialyze’.
liga_writer.erl:18: Expression produces a value of type 'true' | {'error','bad_directory'}, but this value is unmatched
The line in question is:
code:add_path("."),
Where the code is using a stdlib function for its side-effects rather than for its return value. The function does return a value though, and the code would be safer and clearer if the expected value was matched:
true = code:add_path("."),
** Conclusion
Dialyzer is quite simple to use, and helps improve the coherence and clarity of a codebase. As well as the documentation, the Dialyzer chapter of Learn You Some Erlang is worth a read.
Erlang and SMTP: a quick round-up
Sunday, 18th October, 2015
[update 20151022: added selectel/pat]
There seem to be three live projects for using SMTP from erlang:
- Richard Carlsson’s sendmail
- the smtp module in Yaws
- Vagabond’s gen_smtp
- Selectel’s pat
** Richard Carlsson’s sendmail
https://github.com/richcarl/sendmail
This is a simple-but-useful wrapper round sendmail. Consequently, it depends on the host OS having sendmail up & running. Also consequently, it can take advantage of sendmail’s other features (e.g., retrying failed sends). As Richard explained on erlang-questions in 2011:
Often, what you want is more than just SMTP. If there are some network
issues (or your mail server is simply down) at the time your program
tries to send the mail, you usually want your program to still be able
to regard the mail as sent and carry on. This means that the mail needs
to be persistently stored on disk in a spool area and that the MTA
regularly tries to send any outgoing mail that’s been spooled, so it
will eventually be on its way once the problem is resolved. That’s why
we like to rely on sendmail instead. But it all depends on the needs of
your application.
Note: although this is a single script, it is a git repo in its own right, so it can be added as a dependency.
However, as it’s a single-script it doesn’t have anything fancy like a Makefile. I’ve created a fork with a Makefile so I can have it in my erlang.mk Makefile as a dependency: https://github.com/llaisdy/sendmail.
** the smtp module in Yaws
https://github.com/klacke/yaws/blob/master/applications/mail/src/smtp.erl
This is a single-script smtp client for sending emails. It does not depend on (or use) sendmail.
It seems that, to add this as a dependency to a project, it would be necessary to either add Yaws itself as a dependency, or manually copy the smtp.erl script into your own project.
** Vagabond’s gen_smtp
https://github.com/Vagabond/gen_smtp
This is the full Monty: “a generic Erlang SMTP server framework that can be extended via callback modules in the OTP style. A pure Erlang SMTP client is also included.”
** Selectel’s pat
https://github.com/selectel/pat
This connects to a downstream SMTP server to send email messages. An email message is represented by an erlang record.
A morning with elixir
Saturday, 1st June, 2013
After reading Joe Armstrong’s recent blog post on elixir, and the ensuing discussion there and on twitter, I’ve thought a bit about why I don’t like the language. I can’t spend a week with elixir, so the three observations below are after a morning’s reading and watching.
My overall impression is that elixir is a language that makes it easy for people with a ruby background to dabble with erlang. However, after a morning I’ve found at least three things about elixir that would make my own programming life less pleasant (see below). Elixir contains apparently powerful new features (e.g., macros and protocols), but the examples I’ve seen (e.g. in José Valim’s Erlang Factory talk) are not very exciting.
word-like forms as delimiters
# elixir [1] def name ( arglist ) do code end % erlang [2] name ( arglist ) -> code .
I fail to see how [1] is an improvement on [2]. [2] is shorter by a handful of characters but, mainly, [1] uses word-like forms as delimiters, which I think is a very bad idea.
A human reader will read those word-like forms as words (e.g., the English words “do” and “end”), which they’re not. The delimiters “def”, “do”, and “end” delimit the function definition in the same way that “(” and “)” delimit the argument list.
Using word-like forms as delimiters will either/both (a) slow down the human reader as they read these forms as words, or/and (b) make the code harder to read, as the human reader must explicitly remember not to interpret certain word-like forms as words.
cf also lc and inlist or inbits used to delimit comprehensions.
n.b.: the same arguments apply to erlang’s use of “end” as a delimiter for fun and case blocks. Presumably erlang’s excuse was that they ran out of delimiters borrowed from English punctuation, and they didn’t want to overload “.”. I wonder whether some kind of list delimiter might be appropriate (for case at least), e.g.:
R = case f() of
[this -> 1;
that -> 2],
g(R).
The pipeline operator |>
The pipeline operator strikes me as being halfway between useful and troublesome. It would probably be very useful in cases similar to the example Joe gives (repeated below for convenience) — where a series of functions each take and produce a single item of data.
capitalize_atom(X) ->
V1 = atom_to_list(X),
V2 = list_to_binary(V1),
V3 = capitalize_binary(V2),
V4 = binary_to_list(V3),
binary_to_atom(V4).
def capitalize_atom(X) do
X |> atom_to_list
|> list_to_binary
|> capitalize_binary
|> binary_to_list
|> binary_to_atom
end
However, I think if any of the functions in the series take more than one argument, things could quickly get cumbersome. Witness the discussion on Joe’s blog, Joe’s recent tweets suggesting improvements, and the caveat in the elixir documentation.
The simple case above could be done in erlang with a fold:
capitalize_atom(X) ->
lists:foldl(fun(F, Acc) -> F(Acc) end, X,
[fun atom_to_list/1,
fun list_to_binary/1,
fun capitalize_binary/1,
fun binary_to_list/1,
fun binary_to_atom/1]
).
Granted, this is possibly even yuckier than Joe’s version, but using a fold or, more generally, writing a function that walks through a list of funs, gives the possibility of handling errors, using some kind of context dictionary as the passed argument, etc.
I think elixir’s “|>” looks more general than it usefully is.
atoms
In erlang, variables must begin with a capital letter; atoms need special marking only if they start with a capital letter, or contain certain characters, in which case the atom is enclosed in single quotes. In erlang, module names and function names are atoms.
In elixir, variables don’t seem to need any special marking. Atoms /sometimes/ need to be marked with an initial colon. Unless the atom is a function or module name. Unless the module/function is from the erlang standard library. I might have that wrong.
queue:split/2 unsafe!? => queue_split_at_most/2
Tuesday, 9th April, 2013
[updated after discussion on erlang-questions, starting here]
I’ve just discovered that queue:split(N, Queue) causes a crash if N is larger than Queue has items:
1> self().
<0.37.0>
2> Q1 = queue:new().
{[],[]}
3> Q2 = queue:in(a, Q1).
{[a],[]}
4> Q3 = queue:in(b, Q2).
{[b],[a]}
5> Q4 = queue:in(c, Q3).
{[c,b],[a]}
6> queue:split(4, Q4).
** exception error: bad argument
in function queue:split/2
called as queue:split(4,{[c,b],[a]})
7> self().
<0.45.0>
Here’s a safe split:
queue_split_at_most(N, Q) ->
case queue:len(Q) >= N of
true ->
queue:split(N,Q);
false ->
{Q, queue:new()}
end.
A Content-less PUT that returns 201 or 409
Thursday, 14th March, 2013
Thanks to people on the webmachine mailing-list, wmtrace, and the webmachine source (it really does implement the diagram!).
This webmachine resource accepts a PUT request to create a new resource. No content and no content headers are required in the request. A successful request returns 201, and the new resource is accessible at the same url as the PUT. If the resource already exists a 409 is returned.
-module(dragon_resource).
-export([init/1,
allowed_methods/2,
content_types_accepted/2,
accept_content/2,
resource_exists/2
]).
-include_lib("webmachine/include/webmachine.hrl").
init([]) ->
{ok, undefined}.
allowed_methods(ReqData, Context) ->
{['PUT'], ReqData, Context}.
content_types_accepted(ReqData, Context) ->
{[{"application/octet-stream", accept_content}], ReqData, Context}.
accept_content(ReqData, Context) ->
{false, ReqData, Context}.
resource_exists(ReqData, Context) ->
Name = wrq:path_info(name, ReqData),
case dragon:create(Name) of
ok ->
NewReqData = wrq:set_resp_header("Location",
wrq:path(ReqData),
ReqData),
{false, NewReqData, Context};
error ->
{{halt, 409}, ReqData, Context}
end.
The relevant dispatch.conf line is:
{["here", "be", "dragons", name], dragon_resource, []}.
Building Web Applications with Erlang
Monday, 20th August, 2012
Building Web Applications with Erlang: Working with REST and Web Sockets on Yaws
By Zachary Kessin
This is a lovely little book. 133 pages long, it’s slim, readable, modest, concrete and to the point. It doesn’t insist on being comprehensive for the sake of filling shelf inches. The author has a simple story to tell, and he tells it simply.
The book introduces the erlang web server Yaws, and covers the Yaws approach to serving dynamic content, templating (with ErlyDTL), streaming, ReST, WebSockets, and so on.
The book is light enough to be worth reading if you’re mildly interested in Yaws, or in erlang for web development, and it’s concrete enough to have one or two exciting new ideas (at least it did for me).
It’s also just a nice read. I’d like to see a lot more computer books like this one.
Unfortunately, the text is marred by O’Reilly’s usual incompetent or negligent editing, littered with typos, language errors and code inconsistencies.
Putting that aside, especially nice for me were the chapter on file upload, showing how the web application can start processing a file even before the file has been fully uploaded, and the appendix on emacs, with its brief introduction to Distel.
Baby steps with a nif
Sunday, 14th August, 2011
simple_nif is an erlang NIF which takes a list of integers and returns a record, called params, containing the sum, the mean, and the quartiles of the input list:
1> simple:get_params([1,2,3,4,5,6,7]).
{params,28,4.0,{2.0,4.0,6.0}}
The main point of the exercise was the C interface between erlang and the C functions. The file simple_nif.c shows how to parse the input list from erlang into a C array, and how to assemble the results into an erlang tuple to return.
More details in the README.
I am releasing the code under the ISC license.
References
- Erlang NIF documentation
- Erlang NIF tutorial
- pytherl_utils.c: usage of enif_get_list_cell
- Erlang and OTP in Action: Chapter 12 has a section on NIFs
Browsing error logs on a remote node
Wednesday, 18th May, 2011
First, set up your sasl
This config sets up a directory for rolling logs (max ten files, each max 10 megabytes). More configs on the man page.
% erl_config.config
[
{sasl, [
{sasl_error_logger, false},
{error_logger_mf_dir, "/path/to/a/dir/for/erl/logs/"},
{error_logger_mf_maxbytes, 10485760}, % 10 MB
{error_logger_mf_maxfiles, 10}
]
}
].
And when you run erlang, tell it where your config file is:
erl -config /path/to/erl_config -boot start_sasl ... more args ...
n.b.:
- erlang expects the config file to have the extension .config, which you don’t give in the command line.
- the above config is cribbed from Programming Erlang. I was surprised to find that Erlang and OTP in Action does not describe how to configure the sasl error logger.
Connect and browse
Once you’re connected to the above node (see Connecting erlang nodes), you can run rb, the report browser. A little bit of set up is required. See this discussion on stackoverflow, which encapsulates the setup in a function:
%% @doc Start the report browser and reset its group-leader.
%% For use in a remote shell
start_remote_rb() ->
{ok, Pid} = rb:start(),
true = erlang:group_leader(erlang:group_leader(), Pid),
ok.
Connecting erlang nodes
Tuesday, 17th May, 2011
In order to connect to each other, erlang nodes each need a name, they need to share a secret cookie, and if they’re to communicate over the internet, they need access to ports.
The secret cookie can be either set at runtime (as in the examples below), or in each user’s .erlang.cookie file.
For local connection
On the same machine or subnet, each node just needs a short name:
$ erl -sname chico -setcookie marx ... (chico@localhost)1>
For internet connection
Each node must have the following ports available:
- port 4369, used by epmd (the Erlang Port Mapper Daemon, not Erick and Parrish Making Dollars), must be open for both TCP and UDP (n.b.: this is a default).
- another port or range of ports for the erlang nodes themselves. These nodes can be set at run time using the -kernel, inet_dist_listen_min and inet_dist_listen_max flags.
Each node must also use a full name, with either a domain or an IP address:
$ erl -name chico@brothers.org -setcookie longrandomstring -kernel inet_dist_listen_min 9000 inet_dist_listen_max 9005 (chico@brothers.org)1>
Connecting
Erlang nodes are gregarious: as soon as nodes find out about each other, they connect. An easy way to say hello is “ping”:
(chico@localhost)1> nodes(). [] (chico@localhost)2> net_adm:ping(groucho@localhost). pong (chico@localhost)3> nodes(). [groucho@localhost] (chico@localhost)4> ^g User switch command --> r groucho@localhost --> c Eshell V5.7.2 (abort with ^G) (groucho@localhost)1>
You can skip the connection palaver by using the -remsh flag at startup:
$ erl -sname chico -setcookie marx -remsh groucho@localhost ... (groucho@localhost)1>
etc
Introspection GUIs like AppMon and Pman can access any connected node (see the Nodes menu in the toolbar).
